Outsourcing new CPU scores for lobbies
-
Here you can see what it does: https://github.com/FAForever/fa/blob/741febf45a165e257db972fc2104484a51dd799d/lua/ui/lobby/lobby.lua#L5228
-
@giebmasse said in Outsourcing new CPU scores for lobbies:
Here you can see what it does: https://github.com/FAForever/fa/blob/741febf45a165e257db972fc2104484a51dd799d/lua/ui/lobby/lobby.lua#L5228
Thanks.
@Uveso
I am going to use object sizes from https://wowwiki-archive.fandom.com/wiki/Lua_object_memory_sizes, which is a different Lua version, but hopefully not too far off.Ok so if i understand this correctly, this is what the memory benchmark is basically doing (all of the rest seems to be the CPU benchmark, the code below was added by Uveso in his first commit before the CPU benchmark was added back):
var foo = "123456789"; // reference to a 17 (base Lua string size) + 9 byte string var table = {} // dictionary, 40 Bytes per key hash for (1..25 in 0.0008 increments) { table[toString(index)] = foo // a 32bit reference is assigned }So we have a loop with 30k iterations, that assigns the same reference to 30k different hashes, which all are strings converted from floats.
Tables in lua contain hashes that are 40 bytes each, so the total size of the table (not counting any additional bookkeeping structure) is (hash=40 + ref=4) *30k = 120k Bytes, or 120 KB.
So there are a three problems with this benchmark if my understanding is correct:
-
Even if we assume that the Table is 4 times as big as the hashes/references it contains, we still only end up with a memory size of 480KB. This fits entirely in the L2 cache (which is generally going to be around 1 MB), so we are potentially not even filling the L3 cache. I don't know how the Lua interpretation works exactly, but i would be surprised if the CPU even needed to hit RAM at all during this function.
-
Converting floating point numbers to strings is VERY tricky. If not optimized specifically (in C preferably), it can eat up A TON of performance. Now im assuming that
tostringis an optimized function, but that whole benchmark could end up just measuring the time it takes fortostringto execute, instead of having anything to do with memory, even if that function is optimized. -
We are using a dictionary, so the values are going to be sorted by hash. All in all there could be a lof of table indirection and bucket creation going on, so the benchmark might measure the insert performance of Lua tables and hashing, instead of doing anything with RAM.
So best case scenario is that this is measuring L2 cache, but it might not do that at all. Now i don't know a lot about how Lua interpretation works, so if there are any errors in my logic i welcome everybody to tell me.
Of course it is much easier to critisize benchmarks than to make good ones, so i think its very good that you guys implemented something that doesn't just measure arithmetic operations.
-
-
In my mind it would be better to
- either make the table much bigger (and NOT measure the table creation) and then measure the inserts / reads on that table
- save randomized objects inside the table that are much bigger than strings (again, not measung creation time of table and objects), and then do reads into parts of the object to pull the objects into the CPU cache (which would push parts of the table outside of the cache if you read enough objects.)
-
I thought memory is allocated / synced with RAM, regardless if it fits the cache. Do you have a source to read up on?
-
Yeah but if you let the CPU decide to sync the cache whenever it wants (because you don't put pressure on the cache), it might do it after the benchmark ends, or god knows when. But even if it would work, you would only measure RAM write, never read.
You can force the CPU to pull things into the cache that i doesn't have yet in the cache (= cache miss) really only by randomly demanding from the CPU to give you content of memory addresses over a larger area of memory than what would fit into cache.
I have no source on this, is just pick up tidbits here and there, like links from SO like https://stackoverflow.com/questions/8126311/what-every-programmer-should-know-about-memory or just youtube videos. Problem is i have never implemented a interpreted language nor my own HashTable, so i have to make a bunch of assumptions about how tables in Lua work and my understanding is definitely far from complete.
Measuring computer performance is fucking hard xD
-
I vaguely recall the old score being about 120. Now it's reading 108 to 102.
It's a 5600X with 3600 ram. I have the fclock at 1800 (max that that this Zen generation can stablely go). Nothing is traditionally OCed since you don't do that with Zen CPUs.
-
My score is doubled after this update. CPU is Intel I7 7700 with DDR4 RAM. The gamers should trust CPU scores and I'm proposing to do next :
- Use Zlo performace test is present at https://forum.faforever.com/topic/328/cpu-performance-tests
- Check CPU scores
- Prepare some information about hardware.
GOAL: Build a strong relation between CPU score and the test replay time.
===================
My CPU score now is : 270 (after overclocking in BIOS (memspeed up) : 273)
My replaytime of the zlo replay: 18:15 sec
===================
Hardware
CPU: Intel I7-7700
MB ASUS Z270 TUF 2
RAM : 16 GB DDR4
Integrated graphic
-
What was / is your CPU score?
-
@jip I had 141 , I have now 270 . Also I have tried to overclock PC a little and 've got ... 273
-
FX-8350 @ 4ghz
32gb DDR3 (1600mhz)
old: 245
new: 325 !!!
Now I can't play. I simply get kicked from games. -
I investigate the benchmark issue since 2018:
Postby Uveso » 16 Feb 2018, 19:04
Maybe i am the only one with this opinion, but CPU power ist not the mainproblem.Why we have absurd fast CPU's for Supcom and still lag!?!
While having some PC here i did some testing.Surprise surprise, it's RAM speed.
For example; i changed from DDR3 to DDR4 RAM (I have a board with DDR3 and DDR4 slots).
The simspeed was increasing from +5 to +6
I got also good results when overclocking the HT-link (AMD -> connection between Northbridge and RAM) or overclocking the RAM itself (low CAS Latency, 4xBank Interleaving, reduced refresh cycle(yeah, i know, i know...") ))
))Maybe we should try to not waste too much LUA memory in huge arrays
(Memory use from big unit models, LOD settings etc are not influencing the game speed)Some benchmarks to compare:
18328 QuadCore Q8400 @ 2,5GHz
18543 FX-8150 @ 4,2GHz
18545 PhenomII-X4-955 @ 3,8GHz / 200MHz
18547 PhenomII-X4-955 @ 3,8GHz / 211MHz
18559 PhenomII-X4-955 @ 4,0GHz / 200MHz
18576 PhenomII-X4-955 @ 4,2GHz / 205MHz
18585 PhenomII-X4-955 @ 4,1GHz / 200MHz NB 2200
18589 PhenomII-X4-955 @ 4,0GHz / 200MHz NB 2400
18595 PhenomII-X4-955 @ 4,1GHz / 200MHz NB 2400
18645 i7 6700K @ 4.4GHz
18708 i7 4790K @ 4.4GHz
And some words about the memspeed and "overclocking" with lower benchmark sesults:
by Uveso » 07 Mar 2020, 04:06
ZLO_RD wrote: Edit: lol this test is kinda meaningless xD. 3000 beats 3200 with same timings. 2133 has good timings and no latency data, so can't compare results.Yes, this happens if ppl dont know how a PC works and try to overclock.
If you change the speed of your memory then you also need to set the speed from your front side bus (mainboard clock)
This is needed to set the clock for the mainboards north bridge.North Bridge is the memory manager/controller:
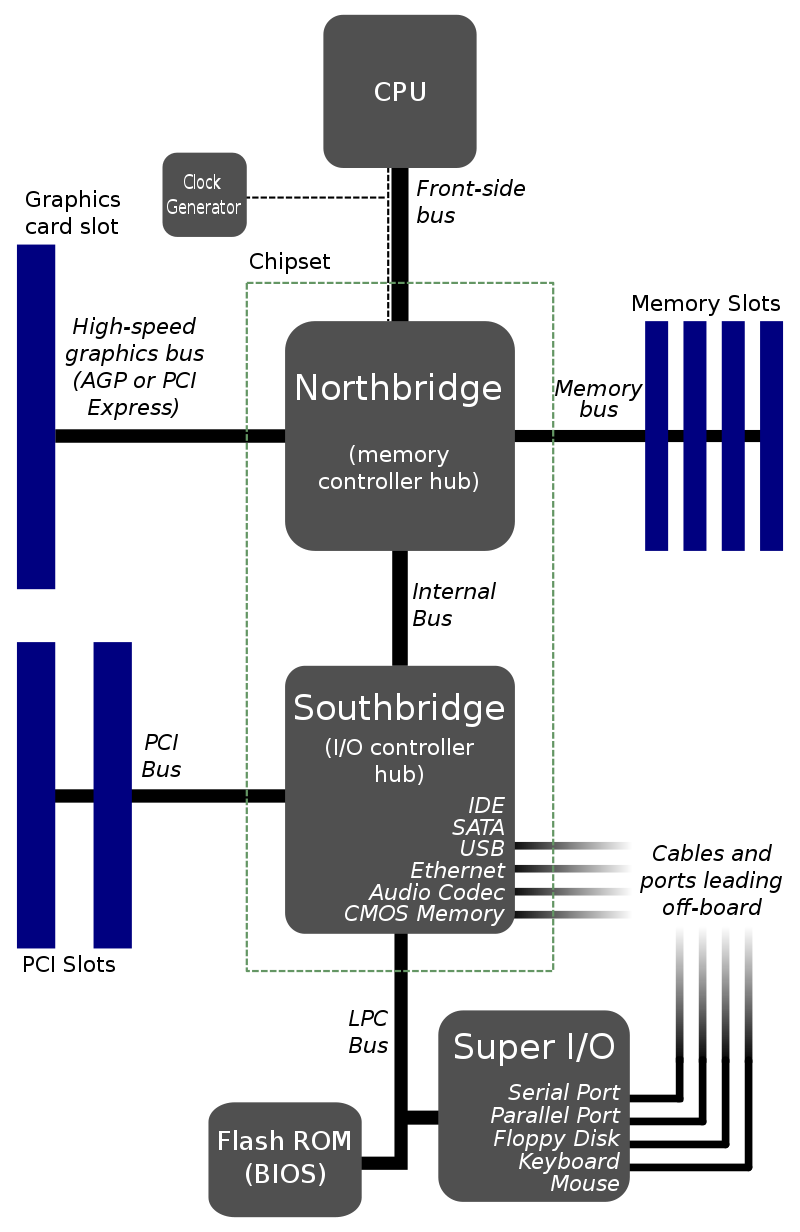
Unsync memory/NorthBridge clock settings will lead to very low memory latency:
You can see here that you will lose about 20% memory speed (Additional Async Latency Offset)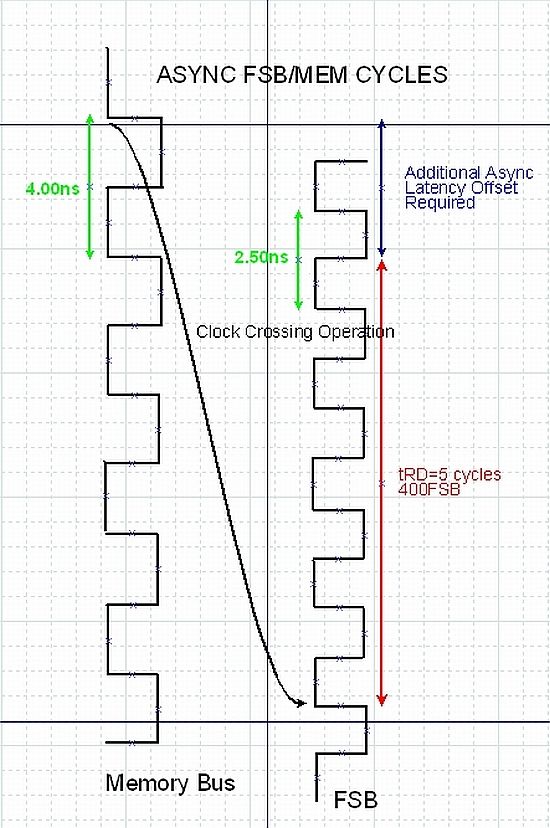
So its no surprise to have fast benchmark results with 3000 clock because 2133 and 3200 are set unsync to North Bridge.
Have in mind we need fast memory "latency" for SupCom, we don't need a high memory clock or high memory throughput.
-
I get that it is really to hard to make a proper benchmark. But this kind reads like you just created some code for the benchmark more or less by chance and the numbers lined up on 4 PCs and thats it. We have no idea what this benchmark is really measuring, and the spikes by people that seem to have normal RAM tell me that his benchmark is neither measuring RAM bandwidth nor latency.
Maybe Supcom is really dependent on caches and maybe the code is measuring L2 and MAYBE thats a good thing, but it seems to break down for a bunch of systems obviously. If those systems are not actually as slow as the benchmark indicates, we should tweak it, and making sure it actually is liekly to hit RAM seems like a good tweak to me.
Even if each table in the actual game fits in cache, the game will use all of them per tick (causing cache pressure), so we cannot use a single table that has typical game size if the game uses a whole bunch of them.
Maybe i can write up an idea later.
-
I have written something that we could maybe use as a base for a better memory benchmark:
https://gist.github.com/Katharsas/89b0e12b3cc751a51d0c278421d6599aI have tried to not run into any of the problems described in my first post. I have taken care not to call the random function inside hot loops in case that this is a slow function.
It consists of 2 benchmark functions operating on a previously filled table. Based on the assumptions about Lua object sizes, it should have a minimum memory size of about 50MB. The Lua interpreter that i used in VSCode will take up 220MB after the table is filled with objects by the setup functions.
I have adjusted the iterations so that each benchmark runs in about 2 seconds in my machine. Now, i don't know how Lua works in the game, so im not sure if this could be ported to the FAF Lua benchmark. It would obviously require normalization / resscaling so that we get numbers that are in a usefull range. However i cannot really see in the FAF source code how the number that we see at the end is calculated and how the time is measured.
-
I've noticed many laptop CPU's stay in their power saving mode when running the newer test (more than before). Would explain some of the spikes.
-
I usually force high-performance mode before I start, tried to run many kinds of benchmarks before CPU test.
Now I randomly got a 260 rating and I'm not doing any new CPU tests
Just to note: before that I had stable 250 rating even in power-saving and balanced modes, and gameplay was normal until late-game, if I accidentally put it in power-saving. -
Old: 210-220
New: 300-310!
8GB of ram
I5-4288U
2.60GHz -
I think we can conclude that one reason for this test to trigger higher scores is because it doesn't cause laptops to go into high performance mode. To me, that sounds like a good thing - as typically a laptop can't sustain that for too long when the GPU is involved.
-
It isn't really a good thing, in all cases I've seen the power saving mode the laptops are in do not reflect the true performance of the laptop in-game, as in the power saving is much lower clock speed even compared to a potentially throttling laptop. Scores between 350 and even 1750, when the laptop true performance would've been somewhere around 250ish or so.
-
Well I just made a few runs with my laptop and surprisingly it's actually scoring better than previously.
Old score was jumping around 185-187, new one seems to be landing at average at 174 mark though depending on run it goes as low as 168 , with the worst run scoring 178.(*funnily enough it was the first run)
That was while having the laptop run on half empty battery in performance mode. There's also little bit more bloat compared to the runs done on the old benchmark but it seems like the new one doesn't care about it.I also agree with Gieb that it's clearly not a good thing if the benchmark can't reliably tell you the expected performance from the players PC.
-
I wasn't referring to power saving mode - I was referring to not being in high performance mode. There is a middle ground, and that is exactly what we want to benchmark in my opinion. At least for my own laptop, it hits high performance mode for the first 15 minutes or so and then it throttles back into 'regular mode'. A typical laptop can not reliably perform at its peak performance - it isn't uncommon that people complain about laptop users.
Lenovo y-50
16GB ram
i7-9750Hbefore: 160 (regular mode, as supreme commander in the lobby doesn't trigger it)
after: 141 with high performance mode because of a single-core background task, 225 on 'regular mode'.Lets gather more information at least - keep the scores coming.