Outsourcing new CPU scores for lobbies
-
@notales said in Outsourcing new CPU scores for lobbies:
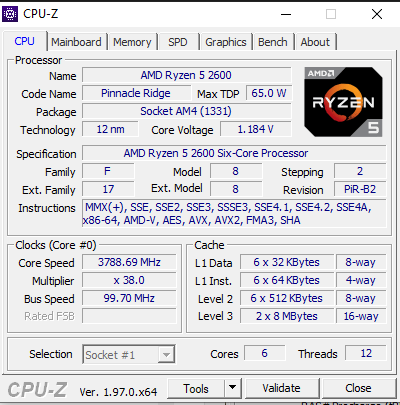
Setup
i5-2310 at 2,95 Ghz
Integrated grafiks
8 GB DDR3CPU score old
241CPU score new
289After 20 min gameplay I ussally got to -1 max at setons
In most dual gap maps -2 when around 45 to 1 hour if im unlucky.
In 99% of all the games I play im not the one slowing games down. Never got enyone wanting me to leave. Now they just dont want me in the lobbys enymore at all
Have 1,1k games played without eny problems, but I gues I wont be allowed to play this game from now on.those are speed evaluation made before the performance changes right ?
-
Old: 178
New: 178Crap tier 3770k @ 4.2Ghz
1080 GTX
16 gigs RAM -
@keyser yes
-
i7-9750H @ 2.6ghz
16gb DDR3old: 162.
new: 131 if it triggers bezerk mode, 180 otherwise.Ryzen 5 3600 @ 3.6ghz
64gb DDR4 (2000mhz)
old: 144
new: 154 -
Old: 95
New: 98Running a Ryzen 5600x with 64GB of DDR4 ram at 1600mhz 16-18-18-38-74 which isn't what I expected, looks like I need to fix my memory speed again since it should be 2400mhz. Wouldn't be surprised if that's my missing 3 points of score.
-
@randomwheelchair
Old score: ~250
New score: 330!!!Cpu: i7-3740QM, 16GB DDR3
Although the game experience didnt change for me, its quite impossible for me to play now: I simply get kicked from games, and explaining the high cpu score doesnt work and severely demoralizing, although I never had lag problems even on Gap-like maps in Endgame phases.
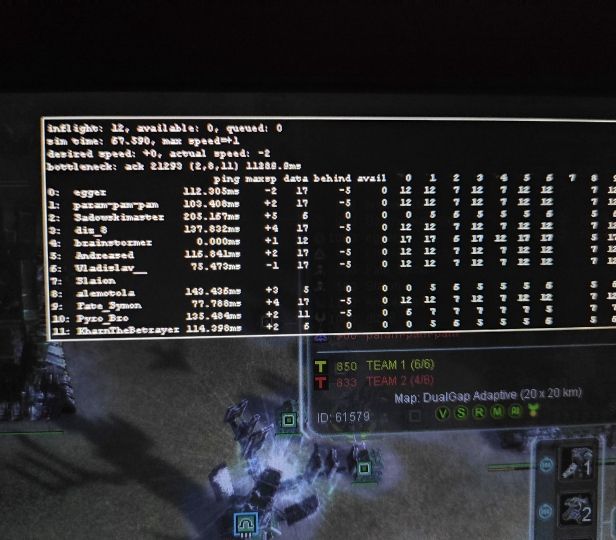
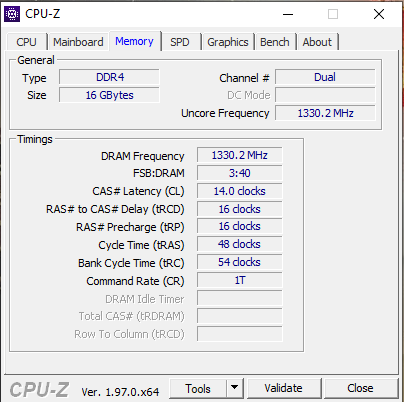
Made this pic in late game just before a desync, its evident I'm not the reason for the bottleneck.Here's my Ram setup:
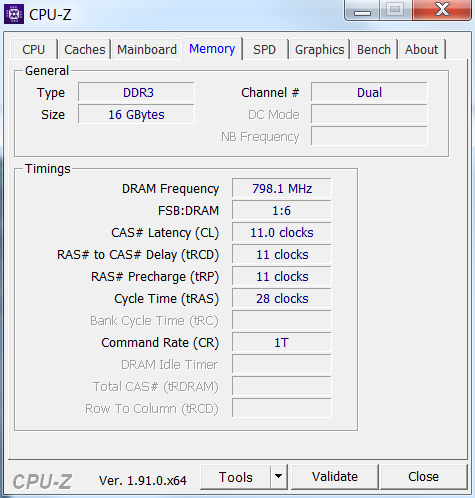
-
This looks like really low RAM Frequency. Have you checked that your RAM runs at the highest clock it can handle?
-
Is there a way to find your old cpu score? I forgot mine!
-
@morax said in Outsourcing new CPU scores for lobbies:
Is there a way to find your old cpu score? I forgot mine!
You could watch an old replay get that version then start the game offline and run it
-
@blackyps
I'm quite sure that's the proper advertised ram speed he would get with that CPU, considering that 1800mhz ram was still considered to be on the higher end of spectrum at the time when his CPU was released. So yeah, 1600mhz ram in a laptop of that age seems like exactly what you would get in mid-higher end laptop. -
Yea it is normal speed for DDR3 memory.
-
I was just asking because there were already multiple people that noticed their ram was clocked lower than it could be
-
Generally i woul'd never advertise UserBenchmark.com, because they are extremly biased against newer Ryzen CPUs, but can you execute their Benchmark and check how your RAM compares? It will tell you how well other people with the same hardware did. We need to find out if your RAM is actually slow for some reason or if there is a problem with the new RAM banchmark.
-
UserBenchmarks: Game 8%, Desk 65%, Work 7%
CPU: Intel Core i7-3740QM - 71.9%
GPU: Nvidia GTX 660M - 7.6%
SSD: Intel 520 Series 120GB - 50.9%
HDD: Seagate ST2000LM015-2E8174 2TB - 60.1%
RAM: Unknown 78.C2GCN.B730C 2x8GB - 55%
MBD: Clevo W3x0ETI understand that 1600MHz DDR3 is outdated, but my config is not subpar and doesn't deserve 330 pts. Can we make a test round of Gap or similar map with some of the admins?
-
Ok well there is no data for this RAM in the Userbenchmark database, so that doesn't give us any information sadly.
-
You have the speed and timings, pretty much all you need to compare ram speed.
-
CPU: Intel I7-7700
MB ASUS Z270 TUF 2
RAM : 16 GB DDR4
Integrated graphic
Old CPU: 141
New CPU: 273
No Lag in game -
Yeah but the question is, why are some new scores so bad? Does the new benchmark heavily tax smaller CPU cache sizes or something? That would explain it maybe?
In my opinion it would be a bit extreme to have CPUs with 6-8MB L3 cache have so much worse scores, if that is the case (Ryzen 3xxx has 16MB per CCX, modern i7 like 20MB).
Or does it maybe just measure bandwith? Thats would be only half of the story, latency can be just as important.
Of course DDR3 has much less bandwith, but it does not have worse latency than DDR4, which is probably kinda more important than bandwith.
We need some information what exactly the new RAM benchmark is measuring.
-
Here you can see what it does: https://github.com/FAForever/fa/blob/741febf45a165e257db972fc2104484a51dd799d/lua/ui/lobby/lobby.lua#L5228
-
@giebmasse said in Outsourcing new CPU scores for lobbies:
Here you can see what it does: https://github.com/FAForever/fa/blob/741febf45a165e257db972fc2104484a51dd799d/lua/ui/lobby/lobby.lua#L5228
Thanks.
@Uveso
I am going to use object sizes from https://wowwiki-archive.fandom.com/wiki/Lua_object_memory_sizes, which is a different Lua version, but hopefully not too far off.Ok so if i understand this correctly, this is what the memory benchmark is basically doing (all of the rest seems to be the CPU benchmark, the code below was added by Uveso in his first commit before the CPU benchmark was added back):
var foo = "123456789"; // reference to a 17 (base Lua string size) + 9 byte string var table = {} // dictionary, 40 Bytes per key hash for (1..25 in 0.0008 increments) { table[toString(index)] = foo // a 32bit reference is assigned }So we have a loop with 30k iterations, that assigns the same reference to 30k different hashes, which all are strings converted from floats.
Tables in lua contain hashes that are 40 bytes each, so the total size of the table (not counting any additional bookkeeping structure) is (hash=40 + ref=4) *30k = 120k Bytes, or 120 KB.
So there are a three problems with this benchmark if my understanding is correct:
-
Even if we assume that the Table is 4 times as big as the hashes/references it contains, we still only end up with a memory size of 480KB. This fits entirely in the L2 cache (which is generally going to be around 1 MB), so we are potentially not even filling the L3 cache. I don't know how the Lua interpretation works exactly, but i would be surprised if the CPU even needed to hit RAM at all during this function.
-
Converting floating point numbers to strings is VERY tricky. If not optimized specifically (in C preferably), it can eat up A TON of performance. Now im assuming that
tostringis an optimized function, but that whole benchmark could end up just measuring the time it takes fortostringto execute, instead of having anything to do with memory, even if that function is optimized. -
We are using a dictionary, so the values are going to be sorted by hash. All in all there could be a lof of table indirection and bucket creation going on, so the benchmark might measure the insert performance of Lua tables and hashing, instead of doing anything with RAM.
So best case scenario is that this is measuring L2 cache, but it might not do that at all. Now i don't know a lot about how Lua interpretation works, so if there are any errors in my logic i welcome everybody to tell me.
Of course it is much easier to critisize benchmarks than to make good ones, so i think its very good that you guys implemented something that doesn't just measure arithmetic operations.
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login